[HDDS-4440] Proposed persistent OM connection for S3 gateway (accepted)
Overview
- Hadoop RPC authenticate the calls at the beginning of the connections. All the subsequent messages on the same call will use existing, initialized authentication.
- S3 gateway sends the authentication as Hadoop RPC delegation token for each requests.
- To authenticate each of the S3 REST requests Ozone creates a new
OzoneClientfor eac HTTP requests, which introduces problems with performance and error handling. - This proposal suggests to create a new transport (in addition to the existing Hadoop RPC) for the OMClientProtocol where the requests can be authenticated per-request.
Authentication with S3 gateway
AWS S3 request authentication based on signing the REST messages. Each of the HTTP requests must include and authentication header which contains the used the access key id and a signatures created with the help of the secret key.
Authorization: AWS AWSAccessKeyId:Signature
Ozone S3g is a REST gateway for Ozone which receives AWS compatible HTTP calls and forwards the requests to the Ozone Manager and Datanode services. Ozone S3g is stateless, it couldn’t check any authentication information which are stored on the Ozone Manager side. It can check only the format of the signature.
For the authentication S3g parses the HTTP header and sends all the relevant (and required) information to Ozone Manager which can check the signature with the help of stored secret key.
This is implemented with the help of the delegation token mechanism of Hadoop RPC. Hadoop RPC supports Kerberos and token based authentication where tokens can be customized. The Ozone specific implementation OzoneTokenIdentifier contains a type field which can DELEGATION_TOKEN or S3AUTHINFO. The later one is used to authenticate the request based on S3 REST header (signature + required information).
Both token and Kerberos based authentication are checked by Hadoop RPC during the connection initialization phase using the SASL standard. SASL defines the initial handshake of the creation where server can check the authentication information with a challenge-response mechanism.
As a result Ozone S3g requires to create a new Hadoop RPC client for each of the HTTP requests as each requests may have different AWS authentication information / signature. Ozone S3g creates a new OzoneClient for each of the requests which includes the creation of Hadoop RPC client.
There are two problems with this approach:
- performance: Creating a new
OzoneClientrequires to create new connection, to perform the SASL handshake and to send the initial discovery call to the OzoneManager to get the list of available services. It makes S3 performance very slow. - error handling: Creating new
OzoneClientfor each requests makes the propagation of error code harder with CDI.
CDI is the specification of Contexts and Dependency Injection for Java. Can be used for both JavaEE and JavaSE and it’s integrated with most web frameworks. Ozone S3g uses this specification to inject different services to to REST handlers using @Inject annotation.
OzoneClient is created by the OzoneClientProducer:
@RequestScoped
public class OzoneClientProducer {
private OzoneClient client;
@Inject
private SignatureProcessor signatureParser;
@Inject
private OzoneConfiguration ozoneConfiguration;
@Inject
private Text omService;
@Inject
private String omServiceID;
@Produces
public OzoneClient createClient() throws OS3Exception, IOException {
client = getClient(ozoneConfiguration);
return client;
}
...
}
As we can see here, the producer is request scoped (see the annotation on the class), which means that the OzoneClient bean will be created for each request. If the client couldn’t be created a specific exception will be thrown by the CDI framework (!) as one bean couldn’t be injected with CDI. This error is different from the regular business exceptions therefore the normal exception handler (OS3ExceptionMapper implements javax.ws.rs.ext.ExceptionMapper) – which can transform exceptions to HTTP error code – doesn’t apply. It can cause strange 500 error instead of some authentication error.
Caching
Hadoop RPC has a very specific caching layer which is not used by Ozone S3g. This section describe the caching of the Hadoop RPC, but safe to skip (It explain how is the caching ignored).
As creating new Hadoop RPC connection is an expensive operation Hadoop RPC has an internal caching mechanism to cache client and connections (!). This caching is hard-coded and based on static fields (couldn’t be adjusted easily).
Hadoop RPC client is usually created by RPC.getProcolProxy. For example:
HelloWorldServicePB proxy = RPC.getProtocolProxy(
HelloWorldServicePB.class,
scmVersion,
new InetSocketAddress(1234),
UserGroupInformation.getCurrentUser(),
configuration,
new StandardSocketFactory(),
Client.getRpcTimeout(configuration),
retryPolicy).getProxy();
This code fragment creates a new client which can be used from the code, and it uses multiple caches for client creation.
-
Protocol engines are cached by
RPC.PROTOCOL_ENGINESstatic field, but it’s safe to assume that theProtobufRpcEngineis used for most of the current applications. -
ProtobufRpcEnginehas a staticClientCachefield which caches the client instances with thesocketFactoryandprotocolas the key. -
Finally the
Client.getConnectionmethod uses a cache to cache the connections:connection = connections.computeIfAbsent(remoteId, id -> new Connection(id, serviceClass, removeMethod));The key for the cache is the
remoteIdwhich includes all the configuration, connection parameters (like destination host) andUserGroupInformation(UGI).
The caching of the connections can cause very interesting cases. As an example, let’s assume that delegation token is invalidated with an RPC call. The workflow can be something like this:
- create protocol proxy (with token authentication)
- invalidate token (rpc call)
- close protocol proxy (connection may not be closed. depends from the cache)
- create a new protocol proxy
- If connection is cached (same UGI) services can be used even if the token is invalidated earlier (as the token is checked during the initialization of the tokens).
Fortunately this behavior doesn’t cause any problem in case of Ozone and S3g. UGI (which is part of the cache key of the connection cache) equals if (and only if) the underlying Subject is the same.
public class UserGroupInformation {
...
@Override
public boolean equals(Object o) {
if (o == this) {
return true;
} else if (o == null || getClass() != o.getClass()) {
return false;
} else {
return subject == ((UserGroupInformation) o).subject;
}
}
}
But the UGI initialization of Ozone always creates a new Subject instance for each request (even if the subject name is the same). In OzoneClientProducer:
UserGroupInformation remoteUser =
UserGroupInformation.createRemoteUser(awsAccessId); // <-- new Subject is created
if (OzoneSecurityUtil.isSecurityEnabled(config)) {
try {
OzoneTokenIdentifier identifier = new OzoneTokenIdentifier();
//setup identifier
Token<OzoneTokenIdentifier> token = new Token(identifier.getBytes(),
identifier.getSignature().getBytes(UTF_8),
identifier.getKind(),
omService);
remoteUser.addToken(token);
....
As a result Hadoop RPC caching doesn’t apply to Ozone S3g. It’s a good news because it’s secure, but bad news as the performance is bad.
Proposed change
We need an RPC mechanism between the Ozone S3g service and Ozone Manager service which can support per-request authentication and accepts
The Ozone Manager client already has a pluggable transport interface: OmTransport is a simple interface which can deliver OMRequest messages:
public interface OmTransport {
/**
* The main method to send out the request on the defined transport.
*/
OMResponse submitRequest(OMRequest payload) throws IOException;
...
The proposal is to create a new additional transport, based on GRPC, which can do the per-request authentication. Existing Hadoop clients will use the well-known Hadoop RPC client, but S3g can start to use this specific transport to achieve better performance.
As this is nothing more, just a transport: exactly the same messages (OmRequest) will be used, it’s not a new RPC interface.
Only one modification is required in the RPC interface: a new per-requesttoken field should be introduced in OMRequest which is optional.
A new GRPC service should be started in Ozone Manager, which receives OMRequest and for each request, the Hadoop UserGroupInformation is set based on the new token field (after authentication).
OzoneToken identifier can be simplified (after deprecation period) with removing the S3 specific part, as it won’t be required any more.
With this approach the OzoneClient instances can be cached on S3g side (with persistent GRPC connections) as the authentication information is not part of the OzoneClient any more (added by the OmTransport implementation per request (in case of GRPC) or per connection (in case of HadoopRPC)).
To make it easier to understand the implementation of this approach, let’s compare the old (existing) and new (proposed) approach.
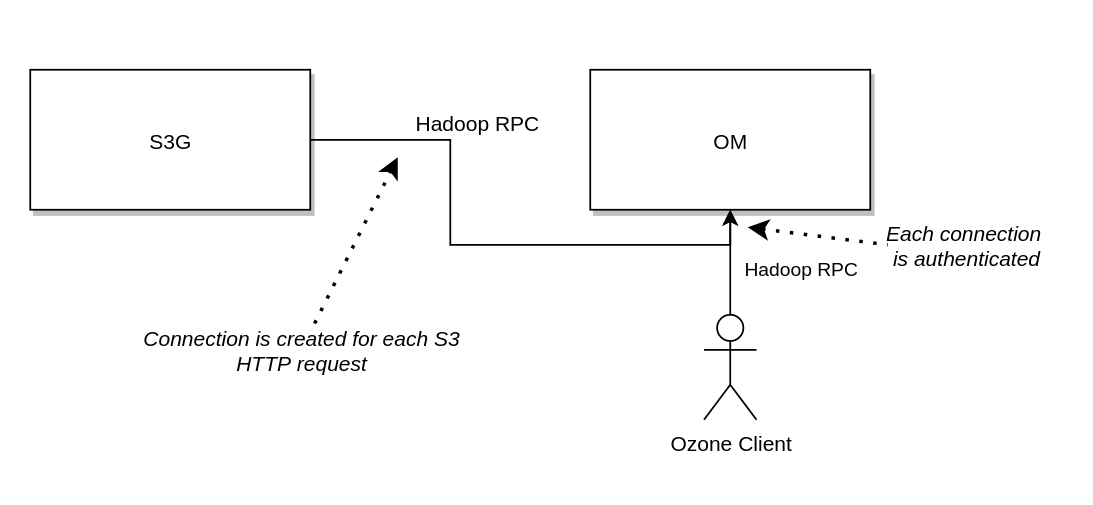
Old approach
-
OzoneClientProvider creates a new OzoneClient for each of the HTTP requests (@RequestScope)
-
OzoneToken is created based on the authentication header (signature, string to sign)
-
OzoneClient creates new OM connection (Hadoop RPC) with the new OzoneToken
-
OM extracts the information from OzoneToken and validates the signature
-
OzoneClient is injected to the REST endpoints
-
OzoneClient is used for any client calls
-
When HTTP request is handled, the OzoneClient is closed
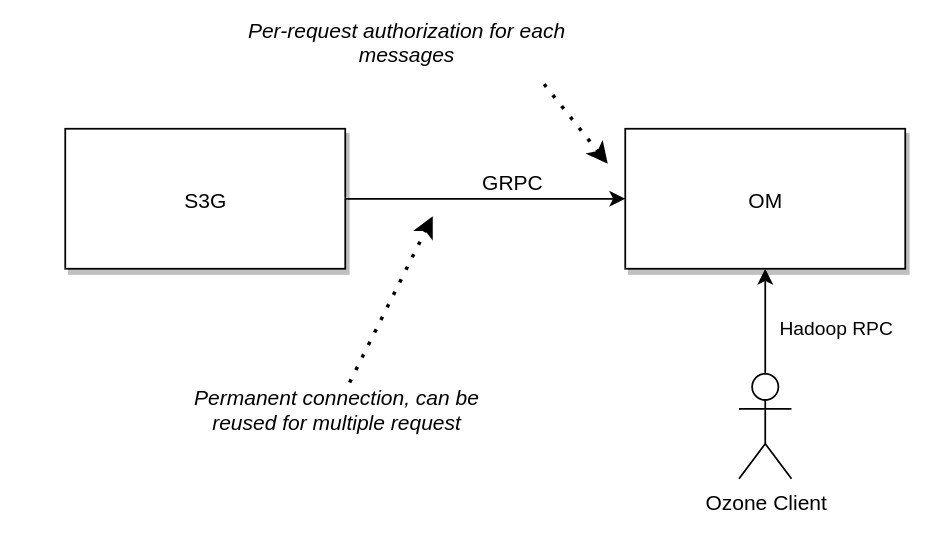
New approach
- OzoneClientProvider creates client with @ApplicationScope. Connection is always open to the OM (clients can be pooled)
- OM doesn’t authentication the connection, each of the requests should be authenticated one-by-one
- OzoneClients are always injected to the REST endpoints
- For each new HTTP request the authorization header is extracted and added to the outgoing GRPC request as a token
- OM authenticate each of the request and calls the same request handler as before
- OzoneClient can be open long-term
Possible alternatives
- It’s possible to use pure Hadoop RPC client instead of Ozone Client which would make the client connection slightly cheaper (service discovery call is not required) but it’s still require to create new connections for each requests (and downloading data without OzoneClient may have own challenges).
- CDI error handling can be improved with using other dependency injection (eg. Guice, which is already used by Recon) or some additional wrappers and manual connection creation. But it wouldn’t solve the performance problem.