Apache Ozone Best Practices at Didi: Scaling to Tens of Billions of Files





Guest post by the Didi Engineering Team. For the full story with detailed slides, see Apache Ozone Best Practices at Didi (PDF).
As Didi's volume of unstructured data surged into the hundreds of petabytes, comprising tens of billions of files, their traditional storage architecture faced severe scalability bottlenecks. This post summarizes how they migrated from HDFS to Apache Ozone, the optimizations they implemented for high-performance reads, and their journey in contributing these improvements back to the community.
The Challenge: HDFS at Scale
Like many data-driven enterprises, Didi relied heavily on HDFS. However, as their data scale grew, they hit the classic "NameNode Limit."
- Metadata Pressure: Storing hundreds of millions of files put immense pressure on the HDFS NameNode memory.
- Block Reporting Storms: With massive file counts, block reporting became a significant overhead.
- Scalability Ceiling: They needed a solution that could handle tens of billions of files without partitioning their clusters into unmanageable silos.
Why Ozone?
They chose Apache Ozone as their next-generation storage engine because it addresses these limitations architecturally:
- Decoupled Metadata: By separating the Ozone Manager (OM) for namespace and Storage Container Manager (SCM) for block management, Ozone scales significantly better than HDFS.
- RocksDB-based Metadata: Unlike HDFS, which relies entirely on heap memory, Ozone stores metadata in RocksDB, removing the memory bottleneck.
- Container Logic: Managing data in "containers" rather than individual blocks reduces the reporting overhead on the SCM.
Today, Ozone has been running in production at Didi for over two years, managing hundreds of PB of storage.
Architecture & Key Optimizations
Migrating was just the first step. To meet Didi's strict latency requirements (especially for "first-frame" read access), they engineered several critical optimizations.
1. Multi-Cluster Routing with ViewFs
To manage the sheer volume of data, they utilized a client-side routing mechanism inspired by HDFS ViewFs. By mapping paths to specific clusters (e.g., vol/bucket/prefix1 → cluster1), they effectively balanced the load and kept the file count in each cluster under 5 billion, alleviating RPC pressure on individual Ozone Managers.
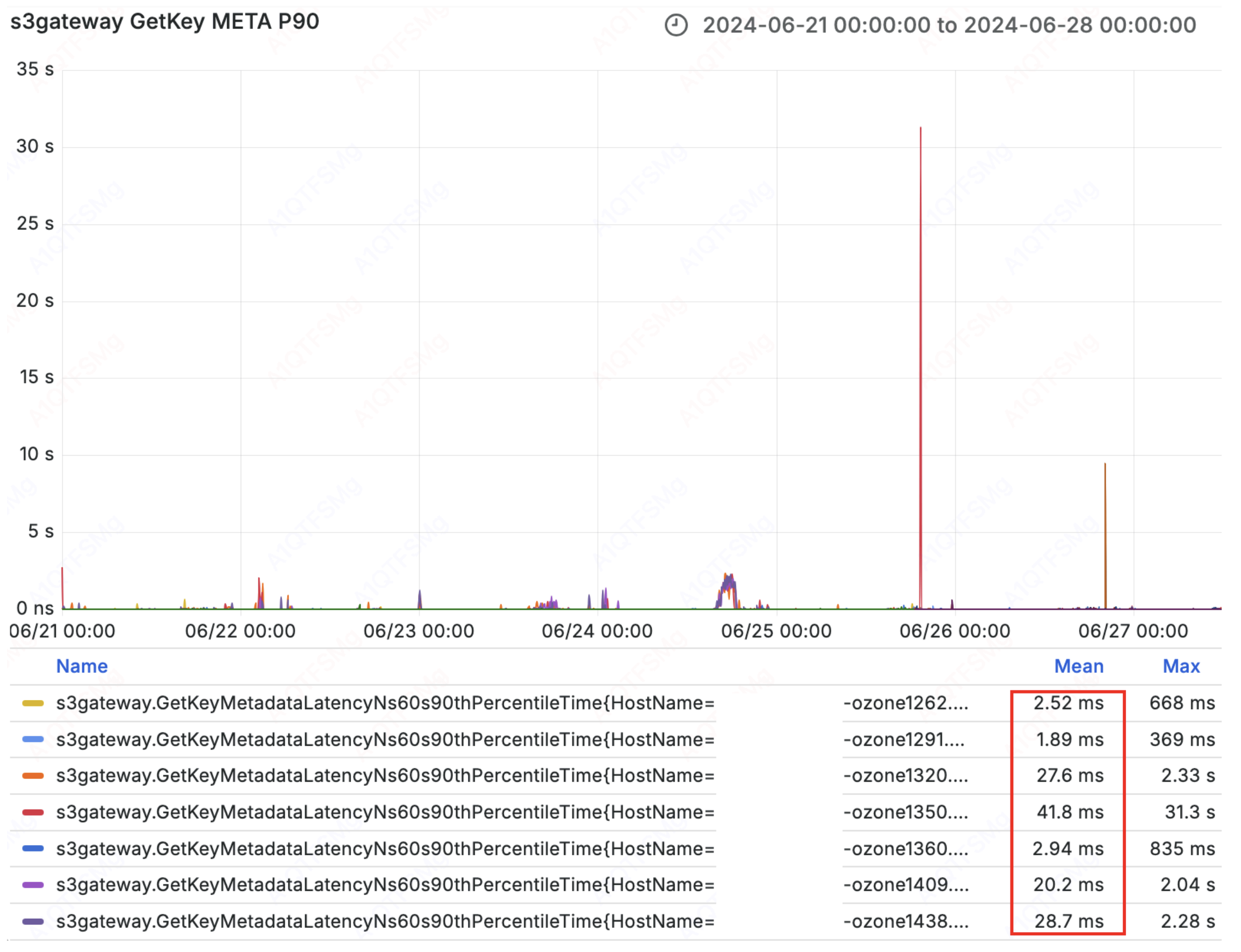
2. Boosting Read Performance: S3G Follower Reads
They observed that the Leader OM often became a bottleneck for S3 Gateway (S3G) requests. To solve this, they implemented a Follower Read strategy.
They introduced a "probe task" in the client (e.g. every 3 seconds) that evaluates:
- Latency: Selects the OM node with the lowest response time.
- Freshness: Checks the lastAppliedIndex to ensure the Follower isn't serving stale data.
Result: The P90 latency for S3G metadata requests (GetMetaLatency) dropped from a weekly average of ~90ms to ~17ms; in best cases, from tens of milliseconds to under 3ms.
3. Heterogeneous Caching (HDD + NVMe)
Didi's clusters use cost-effective hard disk drives, but random reads on small files (tens of MBs) suffered from disk latency. They designed a heterogeneous caching layer:
- Strategy: They cache the first Chunk (1MB) of each block on high-speed NVMe SSDs; for EC (e.g. RS-6-3-1024k) they cache the first stripe (9MB: 6 data + 3 parity) to cover first-frame needs.
- Impact: The 6MB of actual data in that stripe is sufficient for most first-frame requests, dramatically improving read speeds without the cost of all-flash storage.
- Implementation: A custom LRU cache on the Datanode manages this hot data, ensuring efficient space utilization. This caching optimization brought at least 100ms latency improvement in first-frame reads.
4. Concurrency & Lock Optimization
During high-concurrency testing, they identified thread contention issues. Specifically, a spin lock in ChunkUtils#processFileExclusive was causing CPU spikes.
They contributed a fix (see HDDS-11281) that replaced the global lock with a Striped<ReadWriteLock>. This granular locking mechanism reduced lock contention and improved system throughput, yielding a performance gain of at least 50ms per operation in contended scenarios.
Cost Efficiency: Erasure Coding (EC)
With data growing at >1PB per day, the 3-replica cost model was unsustainable. They transitioned to Erasure Coding (EC) using the RS-6-3-1024k policy.
- Storage Savings: Reduced replication factor from 3x to ~1.5x, saving 50% on hardware.
- Challenges Solved: They encountered and fixed issues with deletion backlogs (HDDS-11498), insufficient EC pipelines (HDDS-11209), and Safe Mode logic for EC containers (HDDS-11243), ensuring EC is as robust as replication in production.
Community Contributions
Didi's journey with Ozone has been deeply collaborative. We are proud to highlight that Didi's contributors have brought several key fixes and improvements back to the Apache Ozone community:
- HDDS-11483: Increased S3G buffer size (e.g. to 4MB) to reduce network I/O and improve first-frame latency.
- HDDS-11209: Avoid insufficient EC pipelines in the container pipeline cache (OM must not cache EC pipelines with incomplete Datanodes).
- HDDS-9342: Fixed OM HA crash and restart failure caused by timing inconsistency between applyTransactionMap and double-buffer.
- HDDS-10985: EC Reconstruction failed because the size of currentChunks was not equal to checksumBlockDataChunks.
Summary & Future Work
Apache Ozone has successfully enabled Didi to scale its storage infrastructure to hundreds of petabytes while maintaining high performance and lowering costs.
Looking ahead, Didi is exploring:
- IO_URING: To further enhance asynchronous I/O efficiency.
- SPDK: To accelerate access to RocksDB on NVMe drives for OM and SCM.
Didi thanks the Apache Ozone community for their support and vibrant collaboration. The transition to Ozone has been a game-changer for Didi's big data infrastructure.