高可用 OM
Ozone 有两个元数据管理节点(用于键管理的 Ozone Manager 和用于块空间管理的 Storage Container Management )以及多个存储节点(数据节点)。数据是借助 RAFT 共识算法在数据节点之间复制。
为了避免任何单点故障,元数据管理节点也应该具备高可用的设置。
Ozone Manager 和 Storage Container Manager 都支持 HA。在这种模式下,内部状态通过 RAFT (使用 Apache Ratis )复制。
本文档解释了 Ozone Manager (OM) HA的高可用设置,请查看本页的 SCM HA。虽然它们可以独立地为 HA 进行设置,但可靠的、完全的 HA 设置需要为两个服务启用 HA。
Ozone Manager 的高可用
一个 Ozone Manager 使用 RocksDB 在本地持久化元数据(卷、桶和键)。 Ozone Manager 的高可用版本在功能上完全一致,只是所有的数据都借助 RAFT 共识算法复制到 Ozone Manager 的 follower 实例上。
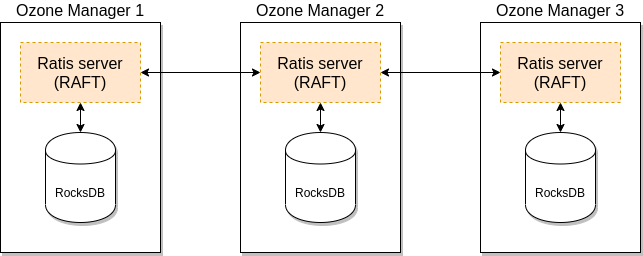
客户端连接到 Ozone Manager 上,而 Ozone Manager 负责处理请求并且安排复制。当请求复制到所有的 follower 上后,leader 就可以给客户端回包了。
配置
可以在 ozone-site.xml 中配置以下设置来启用 Ozone Manager 的高可用模式:
<property>
<name>ozone.om.ratis.enable</name>
<value>true</value>
</property>
一个 Ozone 的配置(ozone-site.xml)支持多个 Ozone 高可用集群。为了支持在多个高可用集群之间进行选择,每个集群都需要一个逻辑名称,该逻辑名称可以解析为 Ozone Manager 的 IP 地址(和域名)。
该逻辑名称叫做 serviceId,可以在 ozone-site.xml 中进行配置:
<property>
<name>ozone.om.service.ids</name>
<value>cluster1</value>
</property>
对于每个已定义的 serviceId ,还应为每个服务器定义一个逻辑配置名:
<property>
<name>ozone.om.nodes.cluster1</name>
<value>om1,om2,om3</value>
</property>
已定义的前缀可用于定义每个 OM 服务的地址:
<property>
<name>ozone.om.address.cluster1.om1</name>
<value>host1</value>
</property>
<property>
<name>ozone.om.address.cluster1.om2</name>
<value>host2</value>
</property>
<property>
<name>ozone.om.address.cluster1.om3</name>
<value>host3</value>
</property>
基于 客户端接口 ,定义好的 serviceId 就可用于替代单个 OM 主机。
例如,使用 o3fs://
hdfs dfs -ls o3fs://bucket.volume.cluster1/prefix/
或 ofs://:
hdfs dfs -ls ofs://cluster1/volume/bucket/prefix/
实现细节
只要请求成功持久化到了大多数节点的 RAFT 日志中,Raft 就可以保证请求的复制。 其中,为了基于 Ozone Manager 实现高吞吐量,即使请求仅持久化到了 RAFT 日志中,它也会立即返回响应。
RocksDB 由后台的批处理事务线程负责更新(这也就是所谓的"双缓冲区",因为当一个缓冲区用于提交数据时,另一个缓冲区用于收集用于下一次提交的新请求)。这里为了使得当前所有数据对于后续请求都可见,即使后台线程还未完全将其写入,这些键数据也会被缓存在内存中。
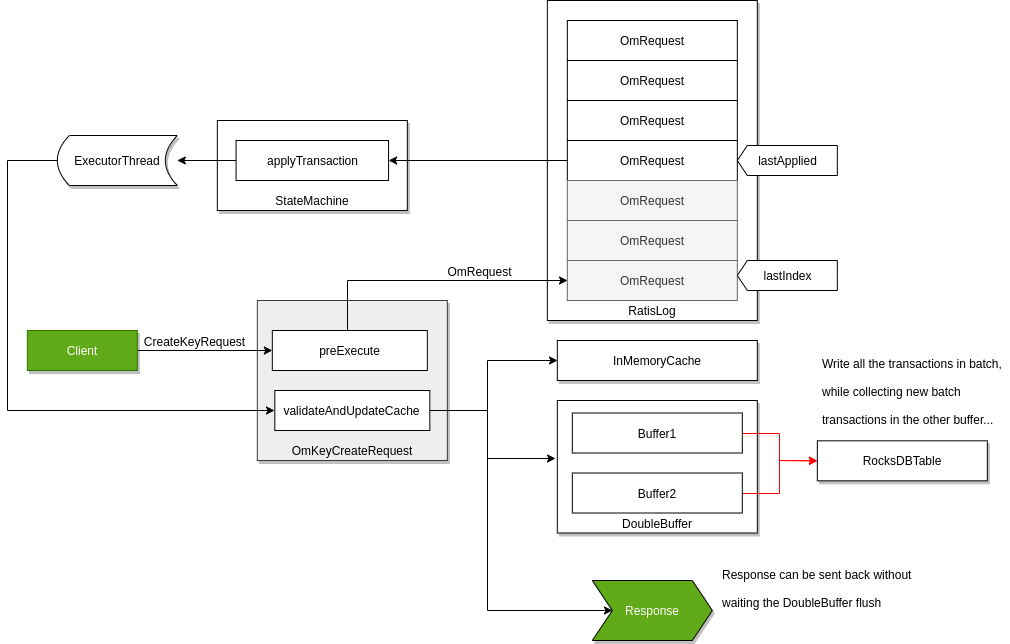
尽管在单独的设计文档中介绍了这种方法的细节,但它仍算作是 OM 高可用的组成部分。
参考文档
- 查看 该页面 以获取详细设计文档;
- Ozone 的分发包中的
compose/ozone-om-ha目录下提供了一个配置 OM 高可用的示例,可以借助 docker-compose 进行测试。