OM High Availability
Ozone has two metadata-manager nodes (Ozone Manager for key space management and Storage Container Management for block space management) and multiple storage nodes (Datanode). Data is replicated between Datanodes with the help of RAFT consensus algorithm.
To avoid any single point of failure the metadata-manager nodes also should have a HA setup.
Both Ozone Manager and Storage Container Manager supports HA. In this mode the internal state is replicated via RAFT (with Apache Ratis)
This document explain the HA setup of Ozone Manager (OM) HA, please check this page for SCM HA. While they can be setup for HA independently, a reliable, full HA setup requires enabling HA for both services.
Ozone Manager HA
A single Ozone Manager uses RocksDB to persist metadata (volumes, buckets, keys) locally. HA version of Ozone Manager does exactly the same but all the data is replicated with the help of the RAFT consensus algorithm to follower Ozone Manager instances.
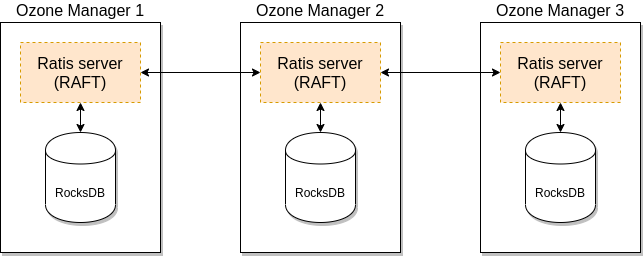
Client connects to the Leader Ozone Manager which process the request and schedule the replication with RAFT. When the request is replicated to all the followers the leader can return with the response.
Configuration
HA mode of Ozone Manager can be enabled with the following settings in ozone-site.xml:
<property>
<name>ozone.om.ratis.enable</name>
<value>true</value>
</property>
One Ozone configuration (ozone-site.xml) can support multiple Ozone HA cluster. To select between the available HA clusters a logical name is required for each of the clusters which can be resolved to the IP addresses (and domain names) of the Ozone Managers.
This logical name is called serviceId and can be configured in the ozone-site.xml
<property>
<name>ozone.om.service.ids</name>
<value>cluster1</value>
</property>
For each of the defined serviceId a logical configuration name should be defined for each of the servers.
<property>
<name>ozone.om.nodes.cluster1</name>
<value>om1,om2,om3</value>
</property>
The defined prefixes can be used to define the address of each of the OM services:
<property>
<name>ozone.om.address.cluster1.om1</name>
<value>host1</value>
</property>
<property>
<name>ozone.om.address.cluster1.om2</name>
<value>host2</value>
</property>
<property>
<name>ozone.om.address.cluster1.om3</name>
<value>host3</value>
</property>
The defined serviceId can be used instead of a single OM host using client interfaces
For example with o3fs://
hdfs dfs -ls o3fs://bucket.volume.cluster1/prefix/
Or with ofs://:
hdfs dfs -ls ofs://cluster1/volume/bucket/prefix/
Implementation details
Raft can guarantee the replication of any request if the request is persisted to the RAFT log on the majority of the nodes. To achieve high throughput with Ozone Manager, it returns with the response even if the request is persisted only to the RAFT logs.
RocksDB instance are updated by a background thread with batching transactions (so called “double buffer” as when one of the buffers is used to commit the data the other one collects all the new requests for the next commit.) To make all data available for the next request even if the background process is not yet wrote them the key data is cached in the memory.
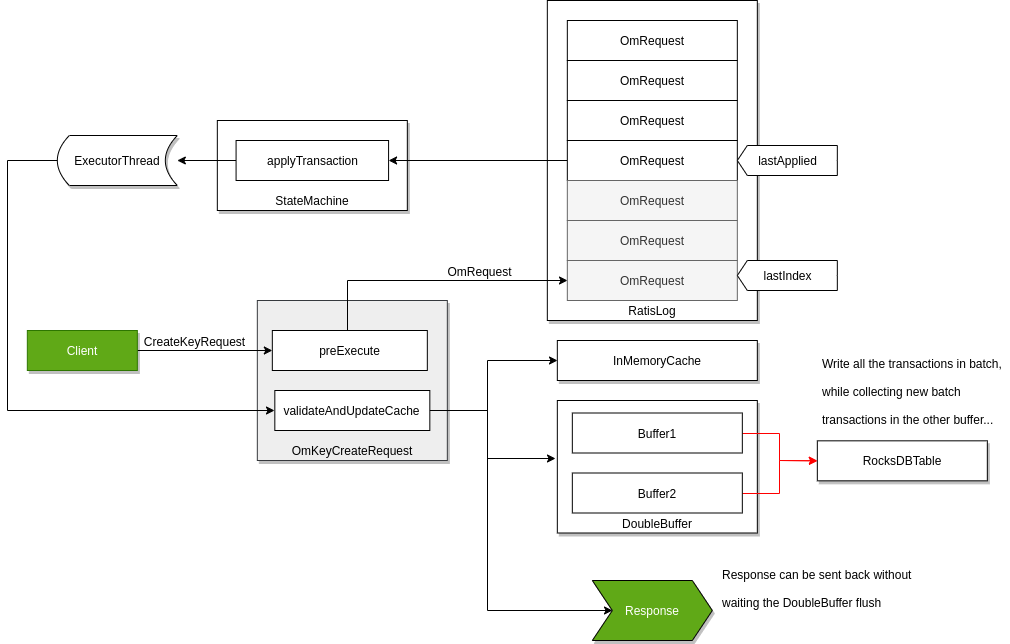
The details of this approach discussed in a separated design doc but it’s integral part of the OM HA design.
OM Bootstrap
To convert a non-HA OM to be HA or to add new OM nodes to existing HA OM ring, new OM node(s) need to be bootstrapped.
Before bootstrapping a new OM node, all the existing OM’s on-disk configuration file (ozone-site.xml) must be updated with the configuration details of the new OM such nodeId, address, port etc. Note that the existing OM’s need not be restarted. They will reload the configuration from disk when they receive a bootstrap request from the bootstrapping node.
To bootstrap an OM, the following command needs to be run:
ozone om [global options (optional)] --bootstrap
The bootstrap command will first verify that all the OMs have the updated configuration file and fail the command otherwise. This check can be skipped using the force option. The force option allows to continue with the bootstrap when one of the existing OMs is down or not responding.
ozone om [global options (optional)] --bootstrap --force
Note that using the force option during bootstrap could crash the OM process if it does not have updated configurations.
OM Decommission
To decommission an OM and remove the node from the OM HA ring, the following steps need to be executed.
- Stop the OzoneManager process only on the node which needs to be decommissioned.
Note - Do not stop the decommissioning OM if there are only two OMs in the ring as both the OMs would be needed to reach consensus to update the Ratis configuration.
- Add the OM NodeId of the to be decommissioned OM node to the ozone.om.decommissioned.nodes.
property in ozone-site.xml of all other OMs. - Run the following command to decommission an OM node.
ozone admin om decommission -id=<om-service-id> -nodeid=<decommissioning-om-node-id> -hostname=<decommissioning-om-node-address> [optional --force]
The _force_option will skip checking whether OM configurations in ozone-site.xml have been updated with the decommissioned node added to ozone.om.decommissioned.nodes property.
Note - It is recommended to bootstrap another OM node before decommissioning one to maintain HA.
References
- Check this page for the links to the original design docs
- Ozone distribution contains an example OM HA configuration, under the
compose/ozone-om-hadirectory which can be tested with the help of docker-compose.