High Availability
Ozone has two leader nodes (Ozone Manager for key space management and Storage Container Management for block space management) and storage nodes (Datanode). Data is replicated between datanodes with the help of RAFT consensus algorithm.
To avoid any single point of failure the leader nodes also should have a HA setup.
- HA of Ozone Manager is implemented with the help of RAFT (Apache Ratis)
- HA of Storage Container Manager is under implementation
Ozone Manager HA
A single Ozone Manager uses RocksDB to persiste metadata (volumes, buckets, keys) locally. HA version of Ozone Manager does exactly the same but all the data is replicated with the help of the RAFT consensus algorithm to follower Ozone Manager instances.
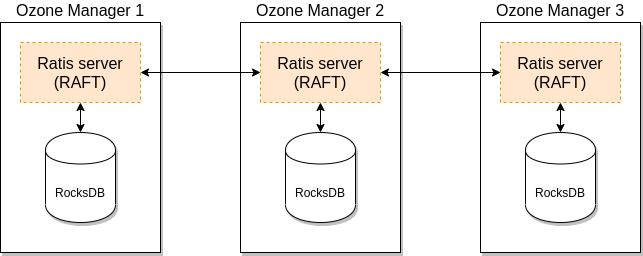
Client connects to the Leader Ozone Manager which process the request and schedule the replication with RAFT. When the request is replicated to all the followers the leader can return with the response.
Configuration
HA mode of Ozone Manager can be enabled with the following settings in ozone-site.xml:
<property>
<name>ozone.om.ratis.enable</name>
<value>true</value>
</property>
One Ozone configuration (ozone-site.xml) can support multiple Ozone HA cluster. To select between the available HA clusters a logical name is required for each of the clusters which can be resolved to the IP addresses (and domain names) of the Ozone Managers.
This logical name is called serviceId and can be configured in the ozone-site.xml
<property>
<name>ozone.om.service.ids</name>
<value>cluster1,cluster2</value>
</property>
For each of the defined serviceId a logical configuration name should be defined for each of the servers.
<property>
<name>ozone.om.nodes.cluster1</name>
<value>om1,om2,om3</value>
</property>
The defined prefixes can be used to define the address of each of the OM services:
<property>
<name>ozone.om.address.cluster1.om1</name>
<value>host1</value>
</property>
<property>
<name>ozone.om.address.cluster1.om2</name>
<value>host2</value>
</property>
<property>
<name>ozone.om.address.cluster1.om3</name>
<value>host3</value>
</property>
The defined serviceId can be used instead of a single OM host using client interfaces
For example with o3fs://
hdfs dfs -ls o3fs://bucket.volume.cluster1/prefix/
Or with ofs://:
hdfs dfs -ls ofs://cluster1/volume/bucket/prefix/
Implementation details
Raft can guarantee the replication of any request if the request is persisted to the RAFT log on the majority of the nodes. To achive high throghput with Ozone Manager, it returns with the response even if the request is persisted only to the RAFT logs.
RocksDB instaces are updated by a background thread with batching transactions (so called “double buffer” as when one of the buffers is used to commit the data the other one collects all the new requests for the next commit.) To make all data available for the next request even if the background process is not yet wrote them the key data is cached in the memory.
![Double buffer](HA-OM-doublebuffer.png
The details of this approach discussed in a separated design doc but it’s integral part of the OM HA design.
References
- Check this page for the links to the original design docs
- Ozone distribution contains an example OM HA configuration, under the
compose/ozone-om-hadirectory which can be tested with the help of docker-compose.